
Атрибут rel=”canonical” поддерживается Яндексом с 23 мая 2011 года. Уже 3 года. Но многим непонятно, что за это атрибут и для чего он нужен.
![]()
Давайте попробуем разобраться для чего он нужен.
На сайте есть основные страницы, точнее страницы с написанными статьями с определенным адресом, на этом сайте это:
http://ichiblog.ru/support-of-the-rel-canonical-robot-yandex/
Но при этом на сайте могут использоваться адреса синонимы. Например, для этой страницы адрес может быть:
http://ichiblog.ru/?p=704
Алгоритмы поисковых систем умеют определять среди таких дублей основную страницу, которая попадет в поисковую выдачу. Но алгоритм может ошибаться, и тогда в поиск попадет служебная или архивная копия страницы.
С помощью атрибута rel=”canonical” можно указывать, какая страница будет предпочтительной. На всех дополнительных страницах создается link с основной. В моем случае на на странице по адресу http://ichiblog.ru/?p=704 вписывается следующий код в раздел head:
<link rel="canonical" href="http://ichiblog.ru/support-of-the-rel-canonical-robot-yandex/">
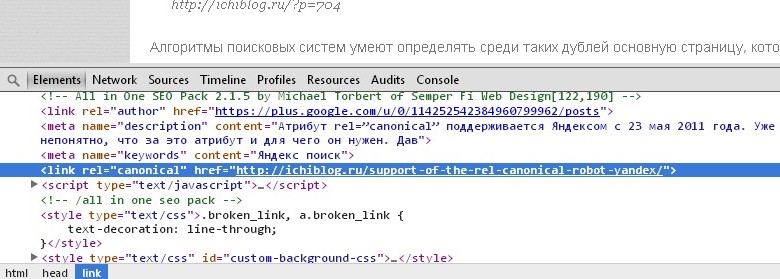
Если Яндекс будет знать о том, что содержание страниц одинаково, он проиндексирует и добавит в результаты поиска только одну из них, выбранную владельцем сайта.
Таким образом можно избежать дублирования содержания страниц в результатах поиска и дать возможность поисковому роботу уделять больше внимания индексированию других, не менее важных страниц сайта.
Ещё одна причина для использования канонических ссылок
При большом количестве дублей можно попасть в фильтр поисковой системы, другими словами попасть в бан Яндекса или Гугл. Тогда в поиске будет лишь одна страница — заглавная.






